概念介绍
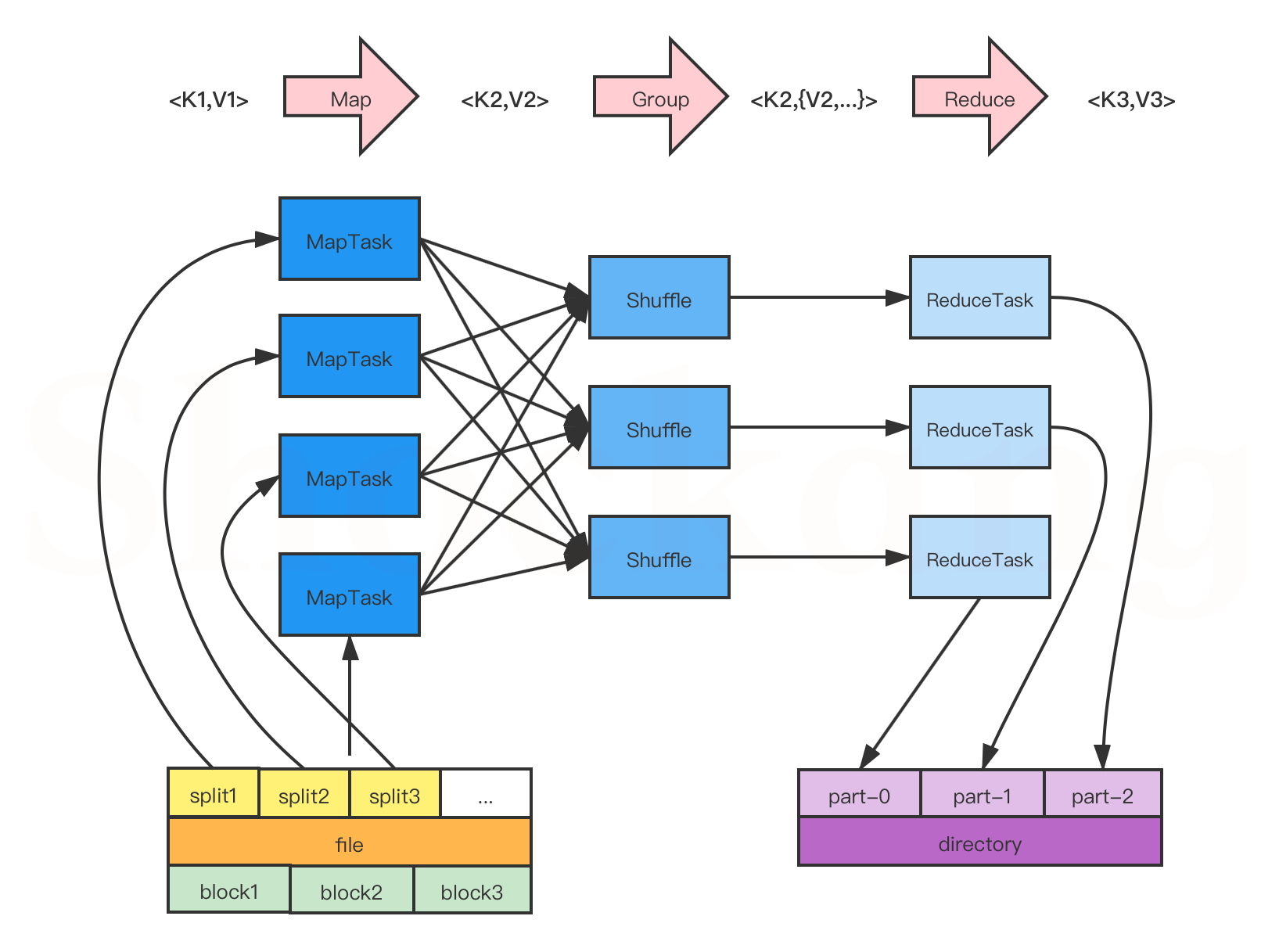
MapReduce 是一种用于处理和生成大规模数据集的编程模型。
它将整个计算过程分为两个核心阶段:Map(映射) 和 Reduce(归并)。在 Map 阶段,数据被分成小块并并行处理,提取出中间的键值对结果;在 Reduce 阶段,框架会将所有具有相同键的数据聚合起来,由用户定义的逻辑进行归并处理,最终输出结果。
MapReduce 的核心优势是:可扩展性强、适合大数据分布式处理、编程模型简单,框架自动负责数据的调度与容错。
通俗地说,它就像是一条流水线:先把原料(大数据)切碎并加工(Map),然后将相同类型的零件集中起来装配成品(Reduce)。
执行流程
实际上MapReduce有三个阶段:Map(映射)、Shuffle(派发)、Reduce(规约)。
在 Map 阶段,每条输入数据(通常是一行文本)被送入用户自定义的 Mapper 类中进行处理。开发者在这个阶段编写逻辑,将每条原始数据“映射”为一组中间键值对(key-value),例如统计词频时,把一句话拆分成每个词,并赋予每个词一个初始计数(如 key 为单词,value 为 1)。这些中间结果不会立即输出,而是会经过分区、排序和归组。
接下来是 Shuffle 阶段,这是 MapReduce 框架自动完成的核心过程。框架会将所有 Mapper 输出的 key 按照值进行聚合,也就是说,把所有具有相同 key 的记录集中在一起,并将它们分发给相应的 Reducer。这个阶段还涉及网络传输(跨节点数据移动)、排序(对 key 进行字典序排列)以及归组(将相同 key 的 value 组成集合),是整个 MapReduce 中性能和资源消耗最多的一部分。
最后是 Reduce 阶段,所有已经被聚合并排序好的数据会输入到开发者自定义的 Reducer 中。Reducer 接收的是某一个 key 以及与它相关联的所有 value 列表,开发者在这个阶段编写聚合逻辑,如累加、求平均、取最大值等。处理后的结果会以最终输出的形式写入 HDFS 或本地文件系统,形成最终的数据处理结果。
所以说,根据以上叙述我们可以得知:在实际的编程中,我们要做的就是编写Map和Reduce操作的代码。同时我们也可以理解到,Map的处理过程应当是(行号, 一行文本) → (key, value);Reduce的处理过程应当是(key, values) → (key, value)。
编程思想
在编写相关Java代码时,我认为最重要的就是理清楚输入输出类型和输入到输出的处理过程,也即(行号, 一行文本) 是怎么变到 (key, value)的,(key, values) 又是怎么变到 (key, value)的。
标准Mapper类
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private Text outKey = new Text();
private IntWritable outValue = new IntWritable();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 1. 读取一行文本
String line = value.toString();
// 2. 分割字段(假设是以逗号分隔的 CSV)
String[] fields = line.split(",");
// 3. 做简单校验
if (fields.length >= 2) {
String someKey = fields[0]; // 例如:用户ID
int someValue = Integer.parseInt(fields[1]); // 例如:交易金额
// 4. 设置输出
outKey.set(someKey);
outValue.set(someValue);
// 5. 输出 key-value 对
context.write(outKey, outValue);
}
}
}
标准Reducer类
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get(); // 累加所有值
}
result.set(sum);
context.write(key, result); // 输出结果
}
}
标准Driver类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.*;
import org.apache.hadoop.mapreduce.lib.output.*;
public class MyDriver {
public static void main(String[] args) throws Exception {
if (args.length != 2) {
System.err.println("Usage: MyDriver <input path> <output path>");
System.exit(-1);
}
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "My MapReduce Job");
job.setJarByClass(MyDriver.class);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}实际上,按照以上标准代码,我们需要做的就是修改输入输出的Key/Value类型和数据处理逻辑。
常见的输入和输出 Key/Value 类型
| 类型 | 说明 | 用途示例 |
|---|---|---|
| LongWritable | 长整型(64位) | 输入 key,通常表示文本行的字节偏移量(offset) |
| IntWritable | 整型(32位) | 常用于输出 value,如计数、数值统计 |
| Text | 字符串类型,Hadoop自带字符串类型 | 输入或输出的 key/value,多用于字符串数据 |
| DoubleWritable | 双精度浮点型 | 处理小数值,如评分、权重等 |
| FloatWritable | 单精度浮点型 | 同上,较少用 |
| BooleanWritable | 布尔型 | 标记型字段 |
| NullWritable | 空值类型 | 不输出 key 或 value 时用,比如只输出 key |